My first production Cloudflare Worker: serverless event tagging for Spesati
Blog post created on 2022-10-31
I’ve written Cloudflare Workers before, but it has mostly been for toying around with concepts and ideas. Nothing serious.
This past weekend this changed. I’ve now formally deployed what I’d consider a Cloudflare Worker in production and it was incredibly easy. Start here if you want to skip the preamble.
Disclaimer: I do work for Cloudflare but the contents of this post were created solely by resorting to publicly available documentation. I’m also using features/resources readily available in the dashboard.
The backstory
There are two circumstances that have led me to this moment.
First and foremost, I manage the tech stack for Spesati, an online only grocery platform that operates in my home region of Sardinia. Spesati has gotten more traction than I ever expected due to the unusual circumstances caused by the Covid-19 pandemic.
Secondly, Apple, over the past couple of years, has been waging war against Facebook and Google with the introduction of App Tracking Transparency. This feature aims to make tracking across apps and websites explicit to the end user. This means that tracking users on Apple devices for advertising purposes has become much harder as, by default, platforms like Facebook cannot collect data from users without consent.
Spesati, like many e-commerce sites, relies heavily on advertising and online campaigns to target potential customers and Apple’s recent privacy changes have directly impacted the business, leading me to find solutions to a growing problem.
For the past several months the results of Facebook and Google campaigns being run by the Spesati team have become terrible to say the least. A problem likely affecting many other businesses and maybe one (of many) contributing factors to Facebook’s not so great earning announcements?
Without going into the privacy debate, I will just mention that Spesati uses advertising to run promotions and retargeting. Customers, as far as we can tell, tend to positively interact with our campaigns as we can target people who have visited the site before and promote specific products they viewed or added to their shopping basket. We do not wish to show adverts to people who have not visited our site first.
Before early 2022, most of the event tracking that powered the campaigns was done with client side JavaScript. Facebook, for example, offers the Facebook JavaScript pixel for easy website integration. Typical tracked events include:
- View content on products or product categories
- Account activation completed
- Checkout initiated
- Checkout completed
Due to the ongoing war between Apple and Facebook et. al, earlier this year, the client side tracking started to fail and the quality of our campaigns plummeted. A new solution was needed.
Enter server side tagging
(From this point onwards I will focus on Facebook, but the same applies to Google, TikTok and other advertising platforms)
To counter the reduced tagging quality of client side scripts, Facebook implements and offers what they call “server side tagging”. Essentially they ask you to integrate your application with Facebook’s API directly from the back end. This is so you can avoid having to deal with client side altogether. More effort on the development side for the business, but the situation was so bad that we obliged.
There was only one catch: to implement this quickly we had to hook into the Facebook API calls directly at page load time* which meant turning off application layer caching. I’ve in fact optimised the Spesati website to integrate well with a CDN layer like Cloudflare by fully caching all the HTML output** and only loading the needed dynamic elements via a much lighter AJAX call.
With this new server side tagging requirement, the whole concept of HTML caching no longer worked, as on every page load, we needed to perform dynamic logic to call Facebooks’ API. Although fine in principle, this caused page load times to shoot up by 2-3 seconds plus***. A web performance disaster.
It quickly became clear that we now had two problems rather than one.
* Facebook does allow you to submit events asynchronously (e.g. via a job that iterates on logs) but this would have been a bigger effort than what we could afford.
** I don’t currently cache the HTML on Cloudflare as on the FREE plan this is a little hard, but when needed, upgrading to a higher plan is a click away.
*** I like to optimise resources and the site runs on a very small droplet. We also have more than 30k products in the database with availability, discounts etc. Things get slow fast hence caching is vital.
Cloudflare Workers to the rescue
How to keep server side HTML caching yet have server side tagging? Turns out Cloudflare’s position in the network really helps in this circumstance and it offers a great computing environment: Cloudflare Workers.
The concept was simple: move tracking logic to a Cloudflare Worker and re-enable HTML caching on the server. The Worker should then simply proxy any request as normal, and, only when needed, submit an event asynchronously to the Facebook event’s API.
An HTTP response header from the server could indicate when to submit tracking to Facebook along with additional metadata. The response header itself could also be cached to avoid impacting page generation performance.
Putting it all together:
- User opens a page on Spesati
- Request reaches a Cloudflare Worker. The Worker fetches the page from origin
- Application server responds with cached content including a special tracking header
- On egress, if the special header is present:
- Remove the header (keep a copy of the contents)
- Send response to the browser
- Submit an event to Facebook with the metadata
Spoiler: it works great.
The code
The whole worker currently stands at 100 lines of code. First, we need an event listener to trigger on incoming requests:
addEventListener("fetch", event => {
try {
return event.respondWith(fetchAndTrack(event));
} catch(e) {
return event.respondWith(new Response("Error thrown " + e.message));
}
});The error logic helps us monitor for problems. Moving to the fetchAndTrack function:
const trackingHeader = "Worker-Tracking";
const botRegex = /(bot1|bot2|botn)/g;
async function fetchAndTrack(event) {
response = await fetch(event.request);
response = new Response(response.body, response);
// Perform tracking only if Worker-Tracking response header is present
if(response.headers.has(trackingHeader)) {
// Only run if not a known bot
const ua = event.request.headers.get('user-agent');
if(!ua.match(botRegex)) {
event.waitUntil(facebookTrack(event.request, response));
}
response.headers.delete(trackingHeader);
}
return response;
}
In prose, we first proxy the request to origin and grab the response. We need to make a copy of the response so that we can remove, if necessary, the additional tracking header that may be sent by the origin. If and only if the header is present, and the request is not coming from a known bot (replace the regex with any bot that may visit your site), we call facebookTrack that will handle submitting the event to Facebook. As we are using waitUntil the function call will not block the processing of the request. The following lines will simply remove the header to avoid leaking unnecessary headers, and provide the response to the browser. Taking a peek at the facebookTrack function:
async function facebookTrack(request, response) {
const pixelId = "REDACTED";
const token = "REDACTED";
const url = "https://graph.facebook.com/v15.0/" + pixelId + "/events?access_token=" + token;
const eventData = JSON.parse(response.headers.get(trackingHeader));
const body = {
data: [
{
event_name: eventData.event_name,
event_time: Math.floor(Date.now()/1000),
event_source_url: request.url,
action_source: "website",
user_data: {
client_ip_address: request.headers.get("CF-Connecting-IP"),
client_user_agent: request.headers.get("User-Agent")
},
custom_data: eventData.custom_data,
contents: eventData.contents
}
]
};
// Prepare request
const init = {
body: JSON.stringify(body),
method: "POST",
headers: {
"content-type": "application/json;charset=UTF-8",
},
};
// Submit
const trackResponse = await fetch(url, init);
const results = await gatherResponse(trackResponse);
console.log(JSON.stringify(body));
console.log(results);
}
The function prepares the JSON object to be submitted to Facebook using the documented format and subsequently submits the request. The gatherResponse provides a string version of the Facebook response that we log for debugging purposes. Console logging can in fact be viewed directly from the Cloudflare dashboard.
And that’s it! The code is far from perfect (yes, I need to move the token and pixelId to environment variables) but it works well and over the past 24 hours at time of writing, I’ve only had 5 errors.
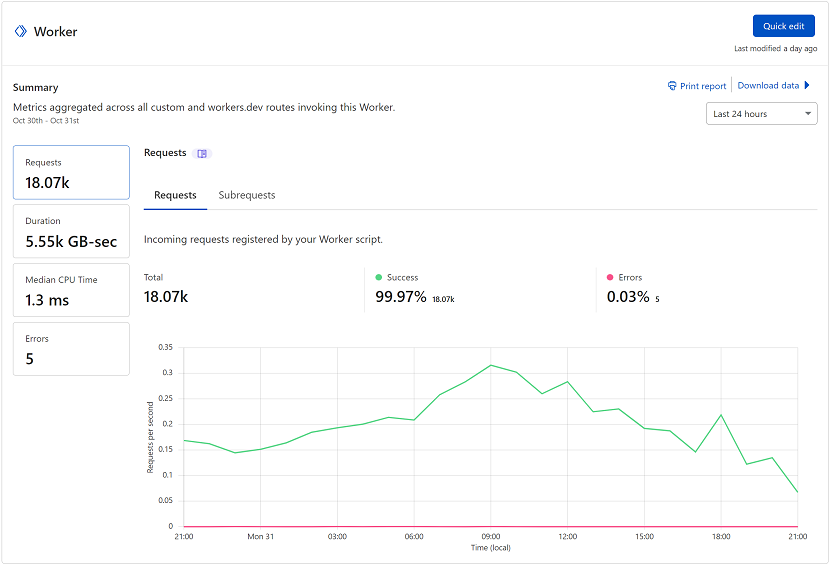
Lessons I learnt along the way
As this was the first time I deployed a Worker in an actual production environment, I did learn a few lessons that I think may come in handy to others.
Make sure you have HTTP route exceptions
To drastically minimise worker execution counts make sure you use routes to define paths where the Worker should not run. This does include writing exceptions for your static content. However, as you can only use the wildcard character ‘*’ in routes at the start or at the end of the route, make sure your static content is served from specific folders. To give you an example, this is what mine looks like:
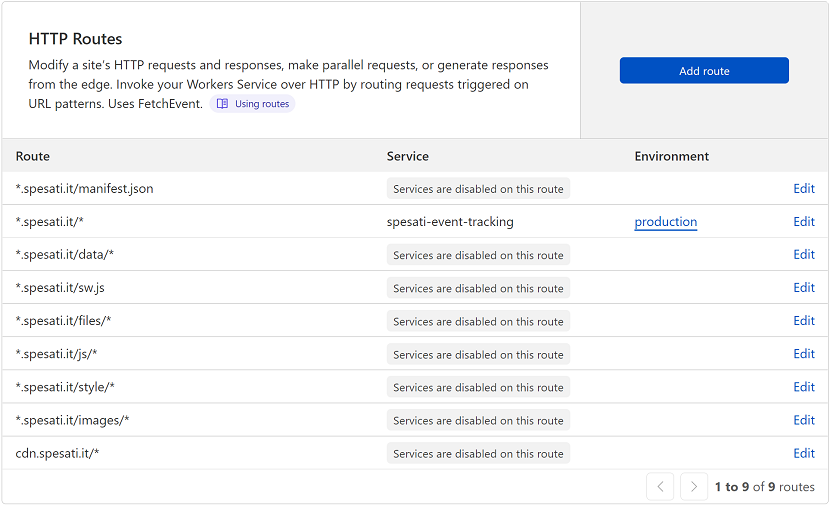
Routers don’t have a specific order, rather, the more specific ones get applied. And if you have many “loose” static files, you are in bad luck...
The dashboard log stream saved me a lot of time
Rather than using the code editor environment to debug and test the worker, I used the dashboard real time logs feature. This was a massive time saver. Additionally, using this feature, you can easily find paths that you need to add to the route table above as you can see the full URL of any request triggering your worker.
Bots bots bots
A big portion of web traffic is bots. And although Cloudflare does offer bot management solutions, it is not available on the free plan. It is still, however, relatively easy to detect the “well behaved” bots. This, again, becomes very important to reduce your worker usage. In my specific use case, I do not care to track bots, and although I cannot exclude bots using HTTP routers, I can at least exclude them from the Facebook tracking, which also reduces the sub request counts being made from the Worker.
In my example above, my bots regex is as simple as:
/(Googlebot|BLEXBot|SemrushBot|AhrefsBot|bingbot|PetalBot|YandexBot|Applebot)/
Client IP
Many tracking and retargeting platforms require you to submit the real client IP. If you are using a reverse proxy the client IP is hidden and you may need to use additional request headers to retrieve the real client IP seen by the proxy. Luckily for us, the worker is actually running on the server that receives the actual request, making accessing the real client IP as simple as looking up the correct header:
request.headers.get("CF-Connecting-IP")This is noteworthy as in my first back end implementation of server tracking I forgot about the client IP issue and I mistakenly submitted Cloudflare IPs to Facebook for quite some time before I noticed.
The future?
I am currently working on moving all server side tagging to Cloudflare Workers: Google, TikTok, Facebook etc. including for logged in users and non cacheable pages such as the checkout flow. I see two major benefits here:
- My application code remains very clean and void of platform libraries/SDKs
- I can eventually remove client side JavaScript altogether increasing website performance
I do also have a long term goal of moving Spesati’s shopping basket logic to Cloudflare Workers - if only time wasn’t an issue. Actually, I believe Spesati could fully run on Workers one day, but one step at a time.